Portfolio item number 1
Short description of portfolio item number 1

Short description of portfolio item number 1
Short description of portfolio item number 2
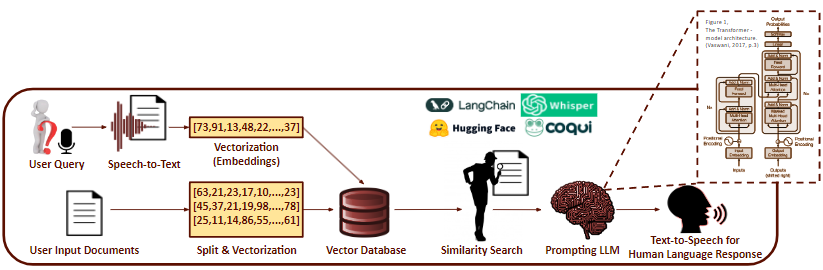
Q&A systems with large language models (LLMs) have shown remarkable performance in generating human-like responses. However, LLMs often suffer from hallucination and generate plausible but incorrect information.
To address this issue, we are developing a Q&A chatbot system that leverages retrieval-augmented generation (RAG). RAG allows users to vectorize and store documents (we are using PDF format) in a grounded database, and conducts similarity and semantic search to retrieve the most relevant information when a user asks a question. The retrieved information is then converted into a human-like response by the LLM.
We are in the research phase of this project and are currently focusing on the following challenges:
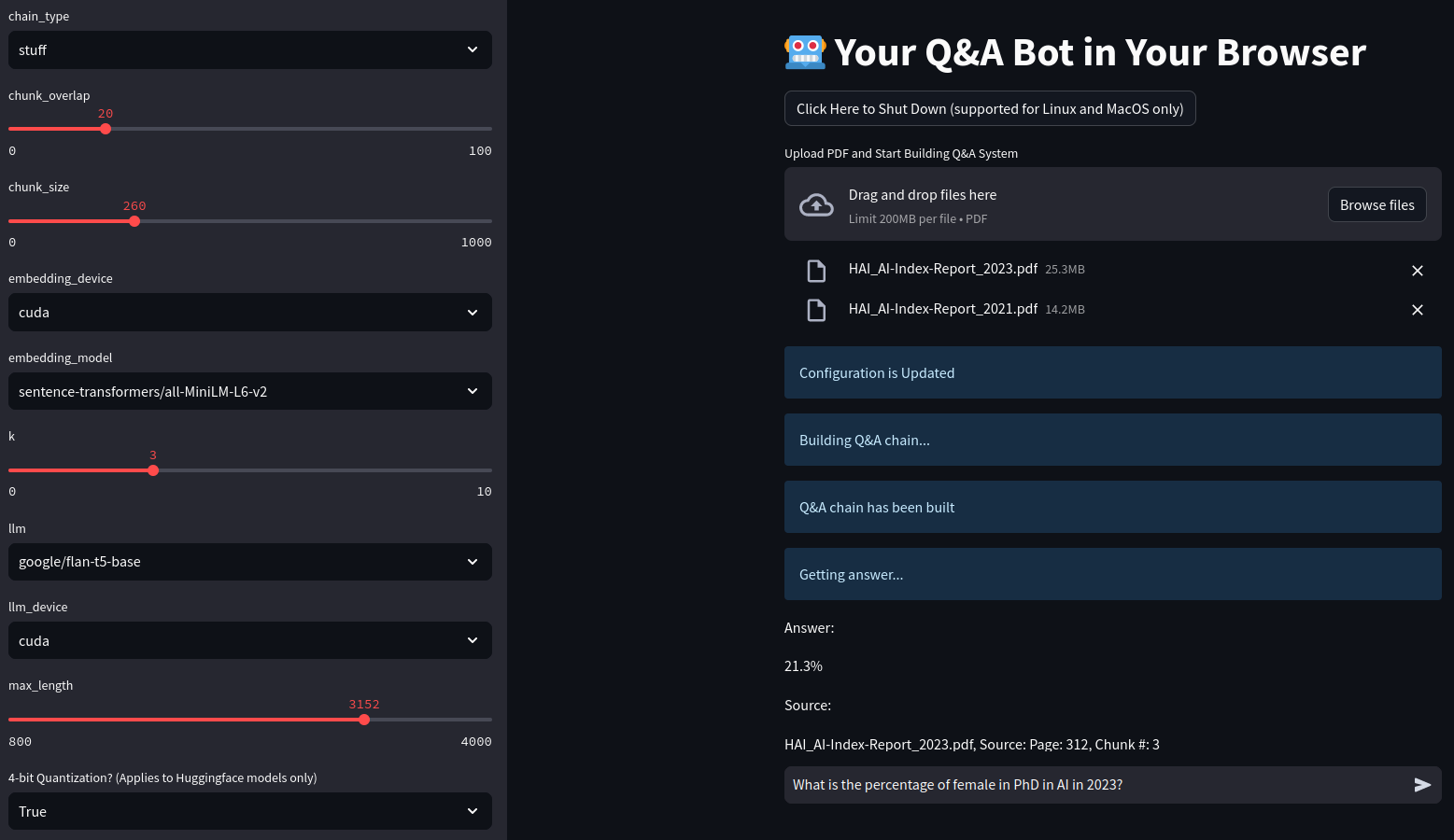
We are currently developing a web application that allows users to upload PDF documents and ask questions. The application is still in the basic stage, but we are planning to refine inference time, memory usage, and user interface.
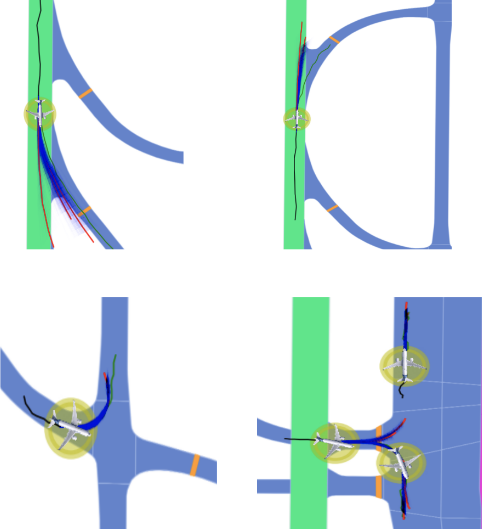
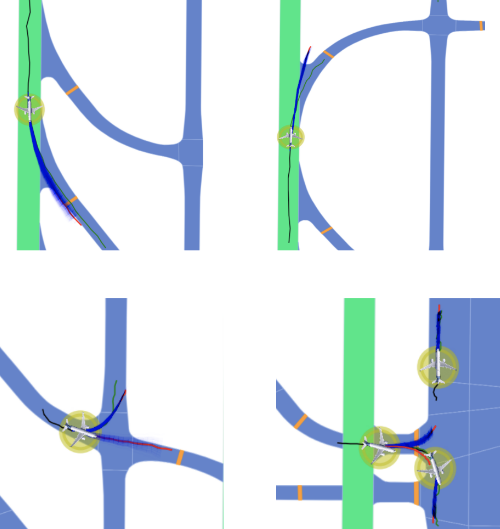
Ensuring safety in airport ground operations is crucial to prevent catastrophic collisions, known as incursions. Human monitoring is currently relied upon to identify and correct potential risks. Motion forecasting models, underexplored in aviation, offer promise in automating the detection of safety-critical situations. This project focuses on studying the impact of different map representations on these models for enhancing situational awareness in aviation safety systems.
The current trajectory data, collected through the Federal Aviation Administration’s (FAA) System Wide Information Management (SWIM) platform, spans 200 days of movement between Seattle-Tacoma Airport (KSEA) and Newark Airport (KEWR).
Specifically, we utilized the SWIM Terminal Data Distribution System (STDDS) for trajectory data, collecting information about aircraft and operational vehicles from 6 FAA systems. These systems include Airport Surface Detection Equipment – Model X, Airport Surface Surveillance Capability, Standard Terminal Automation Replacement System, Runway Visual Range, Electronic Flight Strip Transfer System, and Tower Data Link Services. The data, spanning 200 days from December 1 to June 19, 2023, provides details on altitude, speed, heading, vehicle type, and 2D geographical coordinates. We processed the information to describe positions in a local Cartesian frame unique to each airport, grouping it into 30-second-long scenarios.
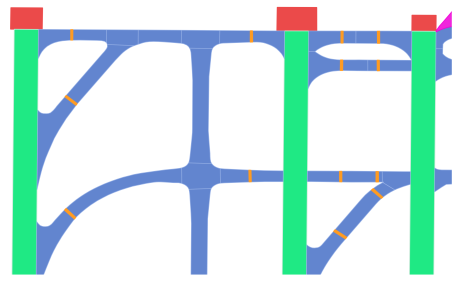
We processed the airport maps into two different representations (1) rasterized images of HD maps and (2) graph-based vectorized maps. Furthermore, we imbued semantic information in their nodes and vertices.
1) Raster Representation: To obtain the raster represen- tation we simply view the polygons formed by the elements of the map as shapes on an image. To retain semantic information, a specific color is assigned to each semantic class.
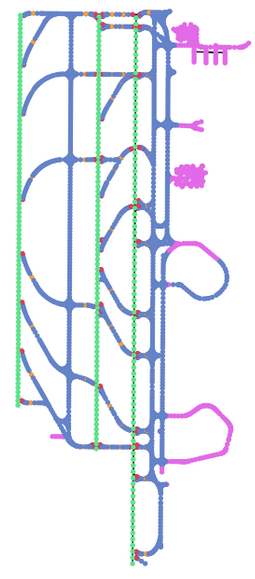
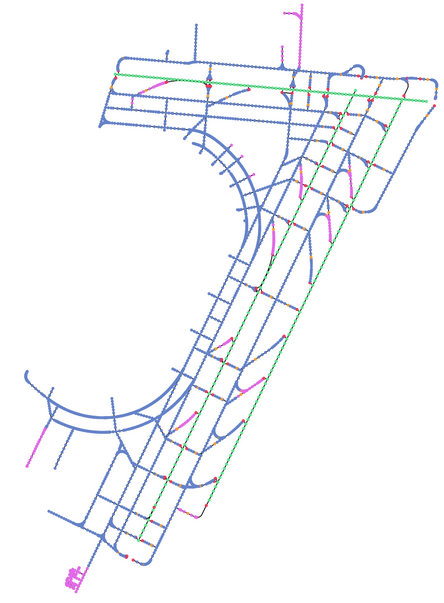
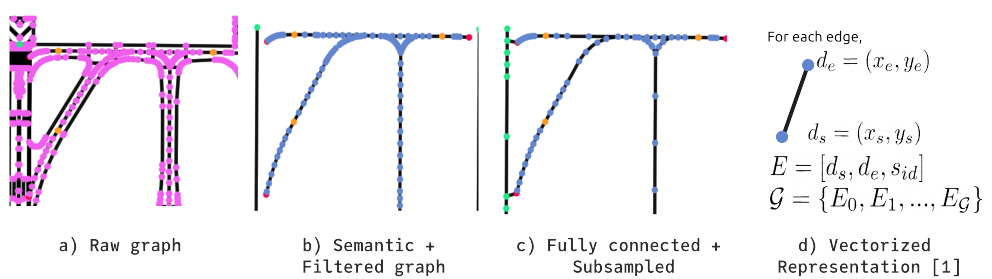
2) Graph Representation: We processed the airport maps by vectorizing them. In the figure below: a) Shows the graph before processing. b) Shows the remaining centerlines after categorizing each node into Runway, Taxiway, Hold-short Line, or exit and eliminating pavement and marking areas. c) Shows the graph after connecting each runway, connecting each exit node to the nearest runway, and eliminating redundant nodes. d) Shows the vectorization process of the graph.
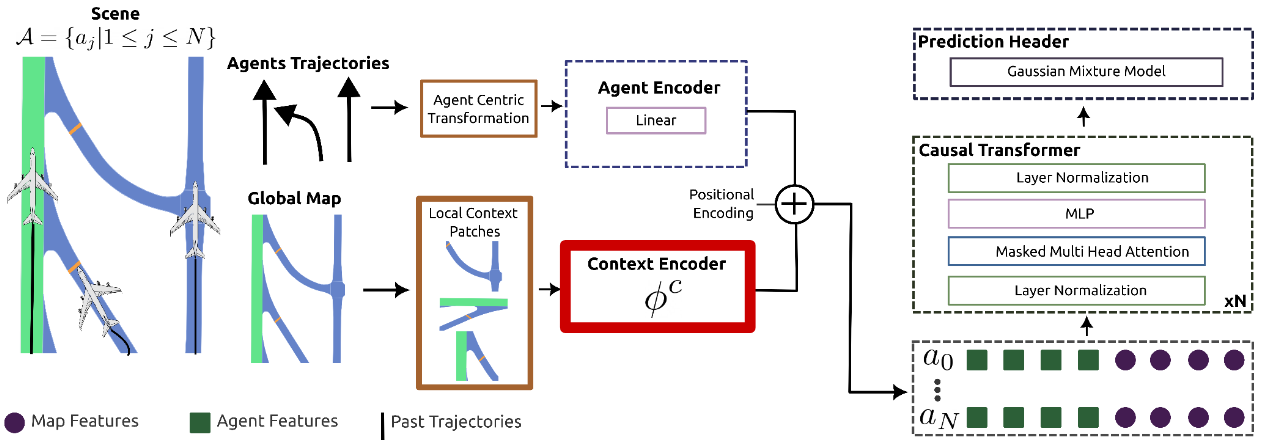
The motion forecasting model architecture adopts a multi-modal joint prediction approach, utilizing an agent-centric representation for trajectories and local context patches. The agent encoder incorporates a linear layer, while the context encoder varies based on the chosen map representation. In this project, we compared CNN-based and MLP-based encoders with and without attention layers for rasterized and graph representations. A GPT-2 style causal encoder performs masked attention over trajectories. Lastly, a Gaussian Mixture Model (GMM) serves as the prediction header, representing future trajectories as a probabilistic distribution for each time step.
To train our motion forecasting models with aircraft trajectory data, we utilized the SWIM (System Wide Information Management) dataset. We employed SWIM-TF, a transformer-based framework that evaluates various scenario representation methods and feature encodings while maintaining the same overall architecture.
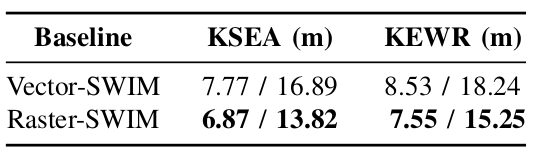
We assessed motion forecasting models by inputting historical aircraft trajectories in airports and corresponding map patches in two representations, rasterized and vectorized. In both cases, raster-based context slightly outperforms the vector-based context. In KSEA, raster-based context has a 0.9 lower ADE and a 3.07 lower FDE than vector-based. In KEWR, ADE differs by 0.98, and FDE by 4.42. Despite the scale of aircraft, these differences are relatively low, suggesting that both context encoding methods are learning similar features from the provided information.
I would like to express my sincere gratitude to Pablo Ortega-Kral for his substantial contributions to this project. Pablo played a pivotal role in the execution of the research, including the primary work and creation of figures presented in this project. His dedication and expertise significantly enriched the outcome of this study.
With the growing focus on urban air mobility, the development of next-generation air mobility systems has become a paramount area of research. This project is motivated from a semi-autonomous approach, wherein pilots remain within the aircraft, supported by advanced co-pilot systems to alleviate their workload during flight operations. To enhance adaptive co-pilot systems, a key aspect is identifying instances when pilots experience high workloads, and one effective method for workload assessment is analyzing pilots’ eye gaze. The instance segmentation approach enables a granular understanding of the pilot’s visual focus, contributing valuable insights into workload distribution during different phases of flight.
Our project tackles the challenge of segmenting instances that pilots inside aircraft would see through two methods: closing sim2real gap and domain adaptation to aviation domain.
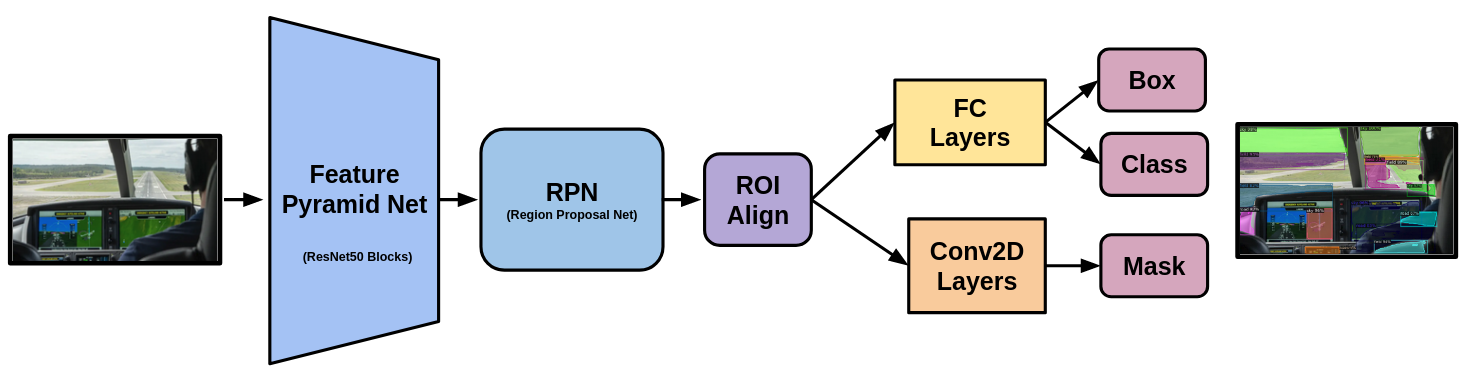
We employed a Mask R-CNN for cockpit view instance segmentation, utilizing a feature pyramid network (FPN) based on ResNet50 blocks to extract feature maps. Subsequently, a region proposal network (RPN) was utilized to identify regions of interest (ROI). A notable feature of Mask R-CNN is the incorporation of ROI Align, representing an improvement over traditional ROI Pooling. This introduction of ROI Align addresses the issue of quantized strides by employing bilinear interpolation, contributing to a more precise localization of features within the regions of interest. We fine-tuned this model with our custom dataset utilizing Detectron2, an open-sourced platform for object detection and segmentation developed by FAIR (Facebook AI Research), on a Mask R-CNN pretrained on the COCO2017 dataset.
We chose to use a convolution-based model for the instance segmentation task. Our hypothesis is that transformer-based models exhibit a relatively relaxed inductive bias compared to other types of models (CNN, RNN, etc.). This is because transformers extract features from input data through attention layers that identify relationships without specific prior knowledge. However, this relaxed inductive bias requires a large dataset to train the model. In contrast, CNNs employ convolution layers, shaping input data into convolved features. In other words, CNNs possess prior knowledge from convolution layers that guide the model to extract features related to high-level and low-level shapes from input images. This prior distribution further shapes the posterior distribution, enabling the model to learn and generate desired outputs with a relatively smaller dataset, which is more suitable for our case.
The segmentation of cockpit views is a novel concept, yet exploring it poses challenges due to the complexities and costs associated with obtaining real cockpit views observed by pilots. To overcome these challenges, we strategically chose to collect data from a flight simulator, reducing costs and addressing safety concerns. The aim of narrowing the sim-to-real gap is to enable the algorithm, trained on simulated data, to effectively and accurately segment instances in real-world cockpit views. This objective enhances the system’s reliability and practical applicability.
Initially, we curated a custom dataset by navigating aircraft in the first-person view using a flight simulator. The entire flight operations were recorded using OBS Studio, an open-source screen capturing software.
We defined six classes (sky, field, road, building, river, monitor) representing typical visual elements encountered by urban air mobility pilots during flight. We generated ground truth labels for each simulated image in our collection by segmenting all objects classifiable into one of our six predefined categories (sky, field, road, building, river, monitor). For this segmentation task, we utilized Make Sense AI, an open-source platform designed for efficient instance segmentation.
The primary focus was to analyze the domain adaptation of our pretrained model to the aviation domain. In our custom dataset, we employed two techniques to ensure robust and generalized adaptation: 1. Collecting different types of aircraft and 2. Applying data augmentation.
We utilized different types of aircraft in the simulation to capture frames of cockpit views.
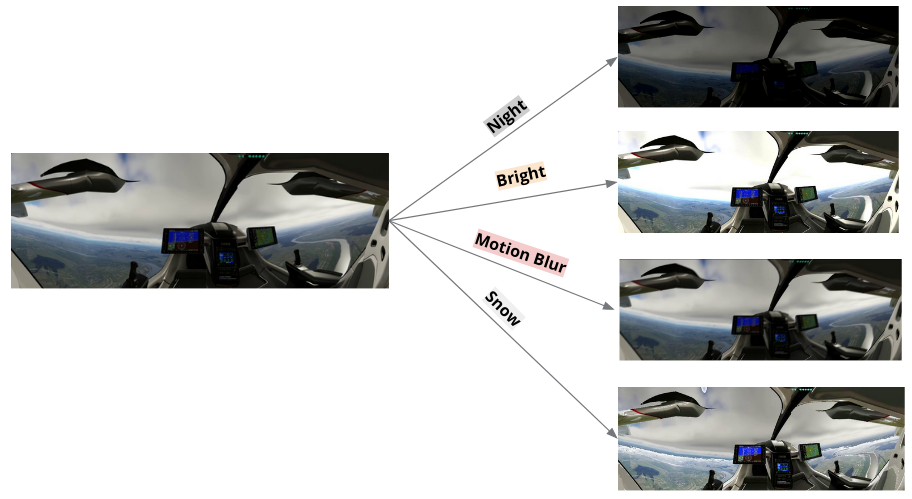
we devised unique image augmentation methods using Kornia and PyTorch’s Transforms, both open-source computer vision libraries. We opted for a combination of augmentations to create filters such as Night, Bright, Motion Blur, and Snow, to simulate diverse view conditions, including different weather and lighting scenarios and resemble the diversity found in real-world conditions.
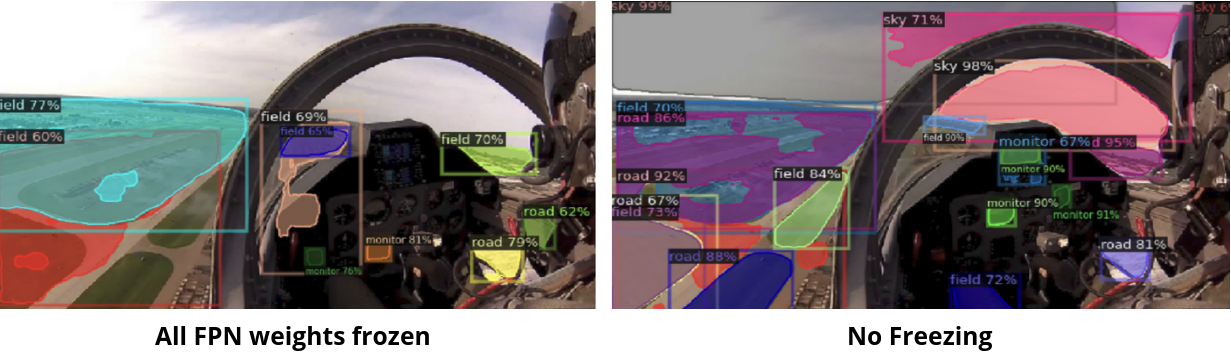
Following the fine-tuning of the model using simulation- derived data, we evaluated its performance on actual flight cockpit images. Visual examination revealed the model’s ability to accurately segment the images into distinct classes. Additionally, we conducted experiments involving fine-tuning tasks, selectively freezing various blocks of the model. Notably, fine-tuning without freezing any weights led to significantly improved segmentation, especially in comparison to maintaining the feature pyramidal network in a frozen state. This implies that fine-tuning the FPN played a pivotal role in enhancing the model’s capacity to effectively comprehend our customized dataset.
While assessing the model’s performance with real-world data, we identified limitations, particularly when testing the F16 fighter jet cockpit in an inverted position. The model struggled to accurately recognize the cockpit orientation, mistaking the sky for the field and vice versa. To enhance robustness to positional variations, we propose to apply geometric augmentation to the training dataset, aiming to improve the model’s ability to recognize instances in non-standard orientations and mitigate the issue of positional invariance.
Our custom dataset and fine-tuned models can be accessed through the QR code below.
Facial emotion recognition (FER) has diverse applications in healthcare, human interactions, and customer satisfaction, playing a crucial role in predicting psychological states during social interactions. Recognizing emotions from facial expressions holds great potential for understanding consumer mental states and improving user satisfaction. We employed machine learning and computer vision techniques to detect and classify human facial emotion expressions.
This was my very first machine learning team project. As a member of a team of five, I was responsible for the entire project pipeline, including development, training, evaluation, and demonstrating the trained model. Here, we trained a baseline CNN with the mini version of AffectNet benchmark and achieved around 70% accuracy on predicting emotions per facial expressions.
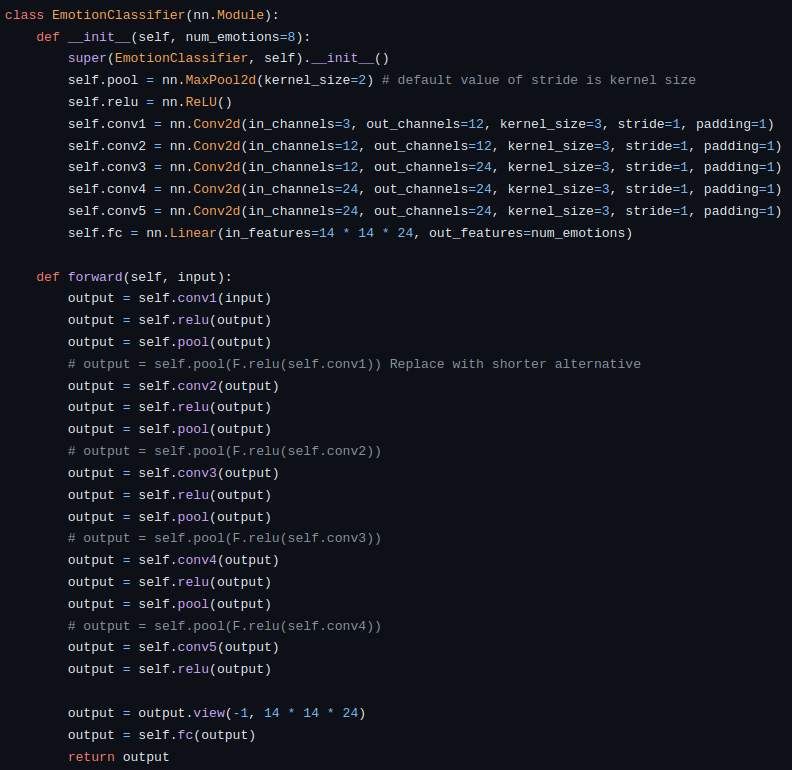
We built a baseline Convolutional Neural Network (CNN) model to identify a person’s emotion based on facial expressions. The project aims to leverage existing machine learning and computer vision approaches to train a model capable of distinguishing and classifying various facial emotion expressions (e.g., ‘happy,’ ‘sad,’ ‘angry’) from given images of human faces. The model was trained and tested using the mini version of the AffectNet benchmark image dataset.
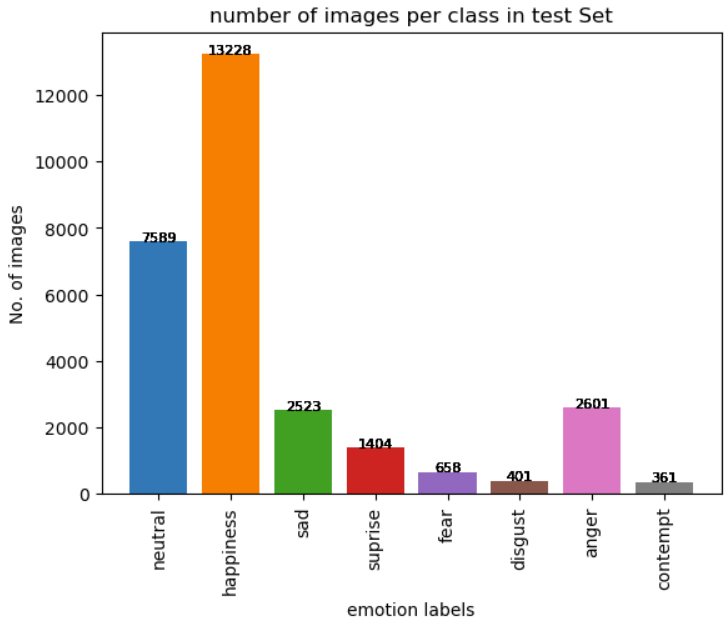
We used the mini version of AffectNet, a benchmark human facial expression dataset. This mini version, comprising 291,651 images, focuses on eight labels. Released since March 2021, it includes manually annotated images with labels ranging from 0 to 7. The images are cropped and resized to 224 x 224 pixels (RGB color). The database contains the 8 expression labels, Arosal/Valence values, and facial landmark points for the training and validation sets. For our project, we specifically utilized the 8 facial expression labels.
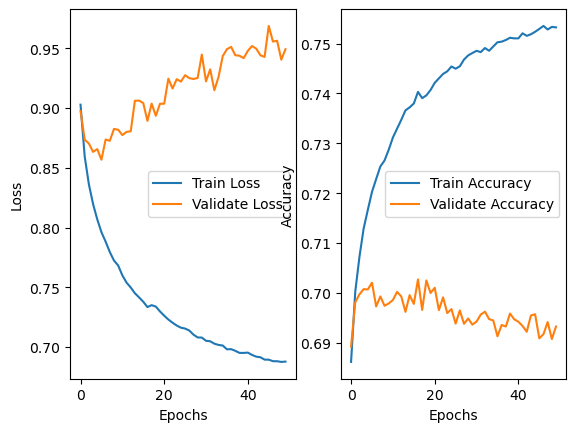
We trained our CNN model for approximately 50 epochs. At that time, we were not familiar with techniques like regularization to prevent overfitting. Additionally, being newcomers to the “Machine Learning” field, we were not yet aware of the concept of “overfitting.” Despite this lack of knowledge, we managed to achieve around 70% validation accuracy, even though the model was overfitting with a training accuracy of 75%. If I were to redo this project, I would implement regularization techniques such as Lasso Regression (L1), Ridge Regression (L2; Weight Decay), batch normalization, dropout, drop block, early stopping, etc. Furthermore, I would employ pixel-wise and geometric image augmentation to introduce variance to the training data, enhancing the model’s ability to generalize.
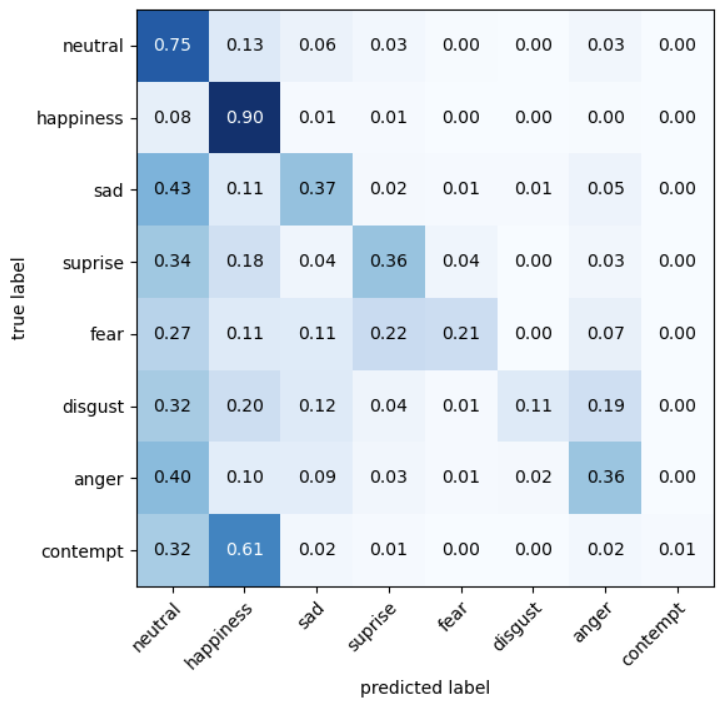
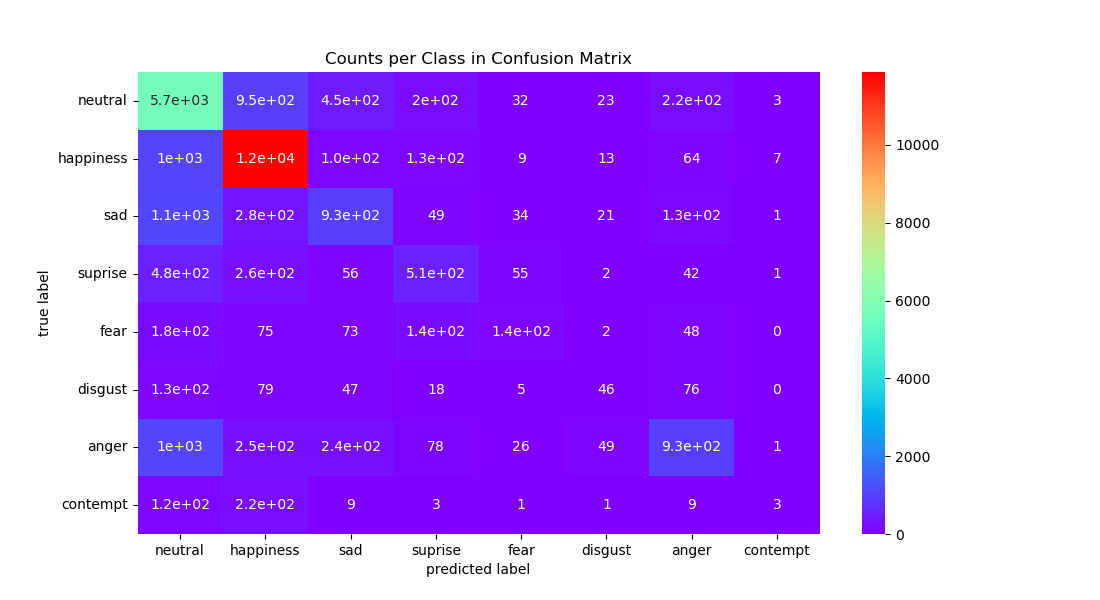
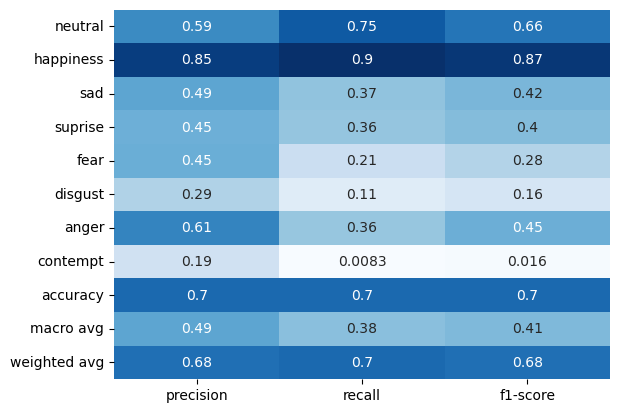
We conducted a comprehensive analysis of our trained model, computing a confusion matrix along with precision, recall, and F1 scores. Upon revisiting the label distribution in the dataset, we observed that a few labels (Neutral and Happy) dominated over 70% of the entire dataset. This led to confusion between contempt and happy emotions. For future work, implementing regularization and data augmentation methods, along with a more sophisticated model architecture such as utilizing residual blocks or a U-shape network, could enhance feature extraction from facial images.
Convolution-based and language-based models have made significant performance strides in the last decade, exemplified by AlexNet surpassing human performance in image recognition in 2015 and the impactful roles played by models like GPT, BERT, and Llama in advancing language understanding. Despite these advancements, the rapid growth in model complexity and size has outpaced the progress in AI deployment technologies, necessitating increased attention to model compression for efficient deployment on smaller devices. With a focus on deploying a large convolution-based model for virtual garment warping on a small device, our project introduces post-training compression methods aimed at maintaining original performance while enhancing efficiency.
As a member of a team of five, I was responsible for compressing a large generative model (72 million parameters) for a virtual garment try-on system based on the model proposed by Parser-Free Virtual Try-on via Distilling Apperance Flows (2021), on an NVIDIA Jetson Nano 4GB. I optimized the model efficiency through various model compression techniques such as quantization, pruning, and model knowledge distillation. Additionally, I conducted sensitivity analysis to evaluate each convolution channel and layer concerning compression techniques.
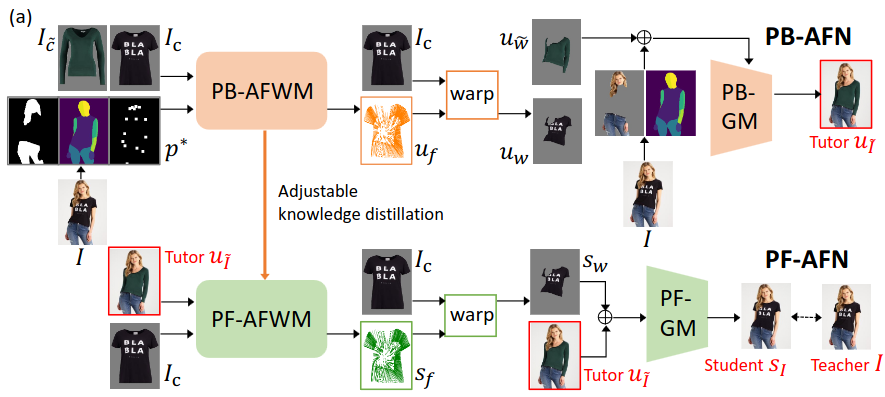
The model we have chosen for the project is Parser-Free Appearance Flow Network (PFAFN). This model has over 70 million parameters and aims to warp input clothe and person images to output an image of the person wearing the clothe. The model comprises two modules, a genera- tive model (43 million parameters) and a apperance flow warping model (29 million parameters).
The training data is the clothes image Ic and the image I of a person wearing the clothes. Parser-based network PB-AFN randomly selects a different clothes image I ̃c to synthesize the fake image uI e as the tutor. The tutor uI e output and the clothes image Ic as inputs to train the parser- free network PF-AFN, where the generated student sI is directly supervised by the real image I. Please note that al- though the original process encompassed multiple stages of training, including both the teacher and student networks, our emphasis was primarily on the PF-AFN stage.
We selectively reduced or ’silenced’ the activity of each block via structured pruning. By doing so, we could ob- serve how the output quality changes and identify which as- pects of the output are most affected when different levels of our system are less active or more ’sparse’.
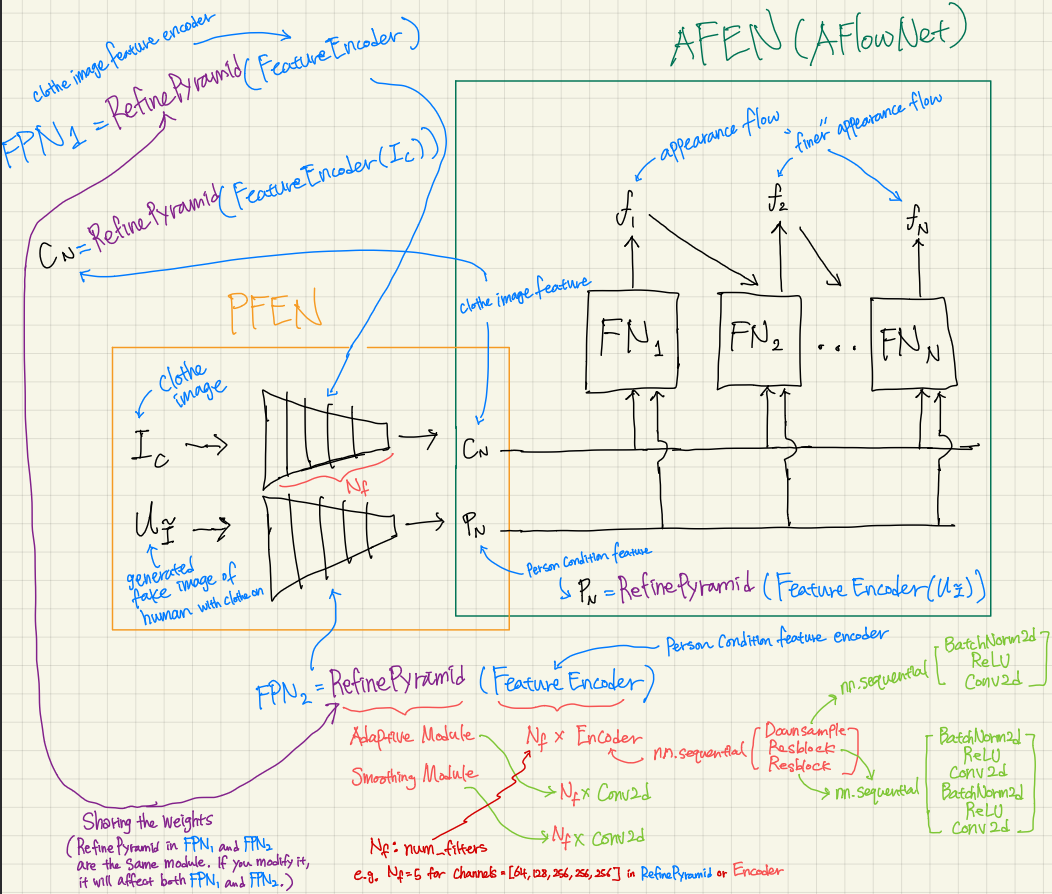
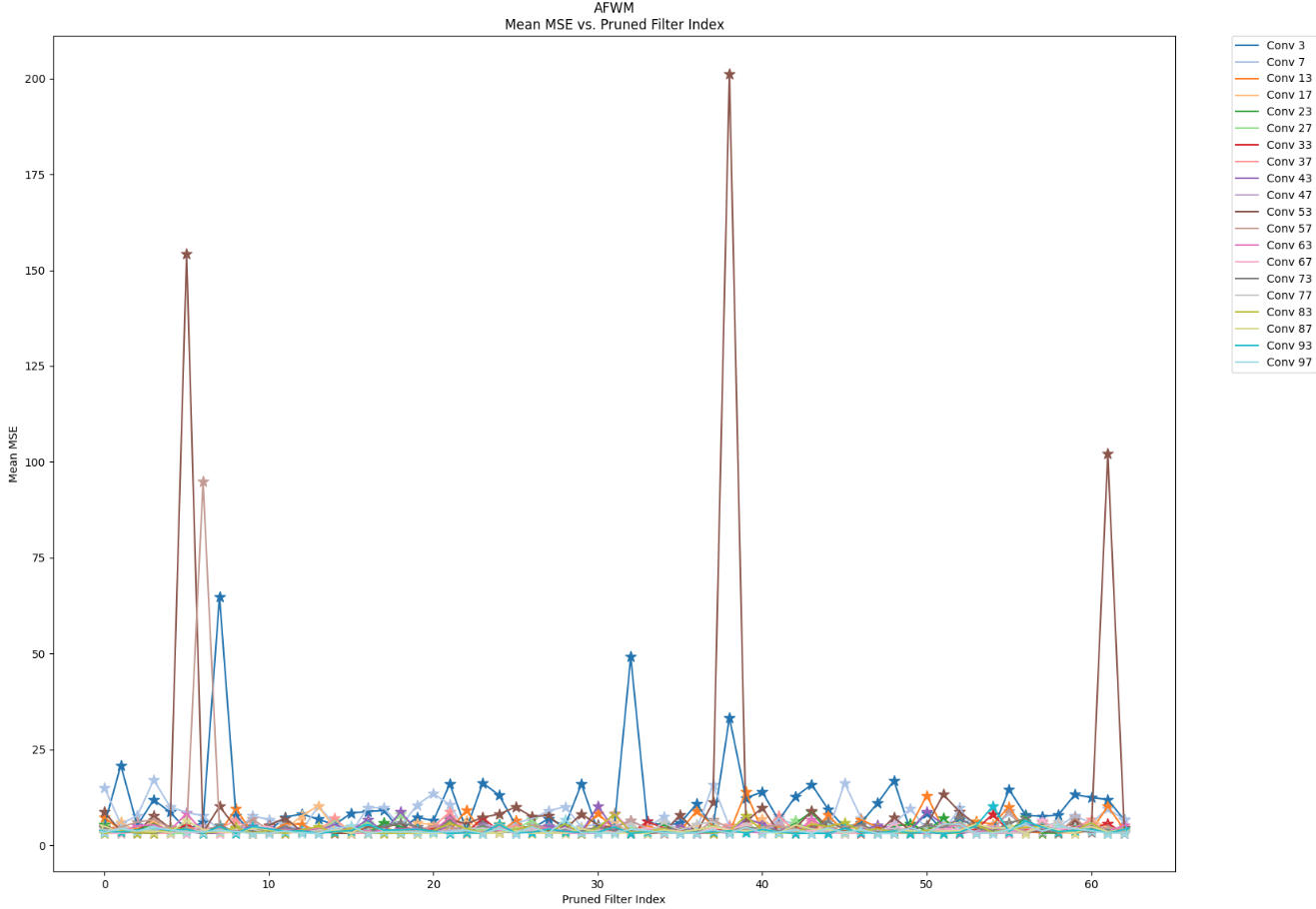
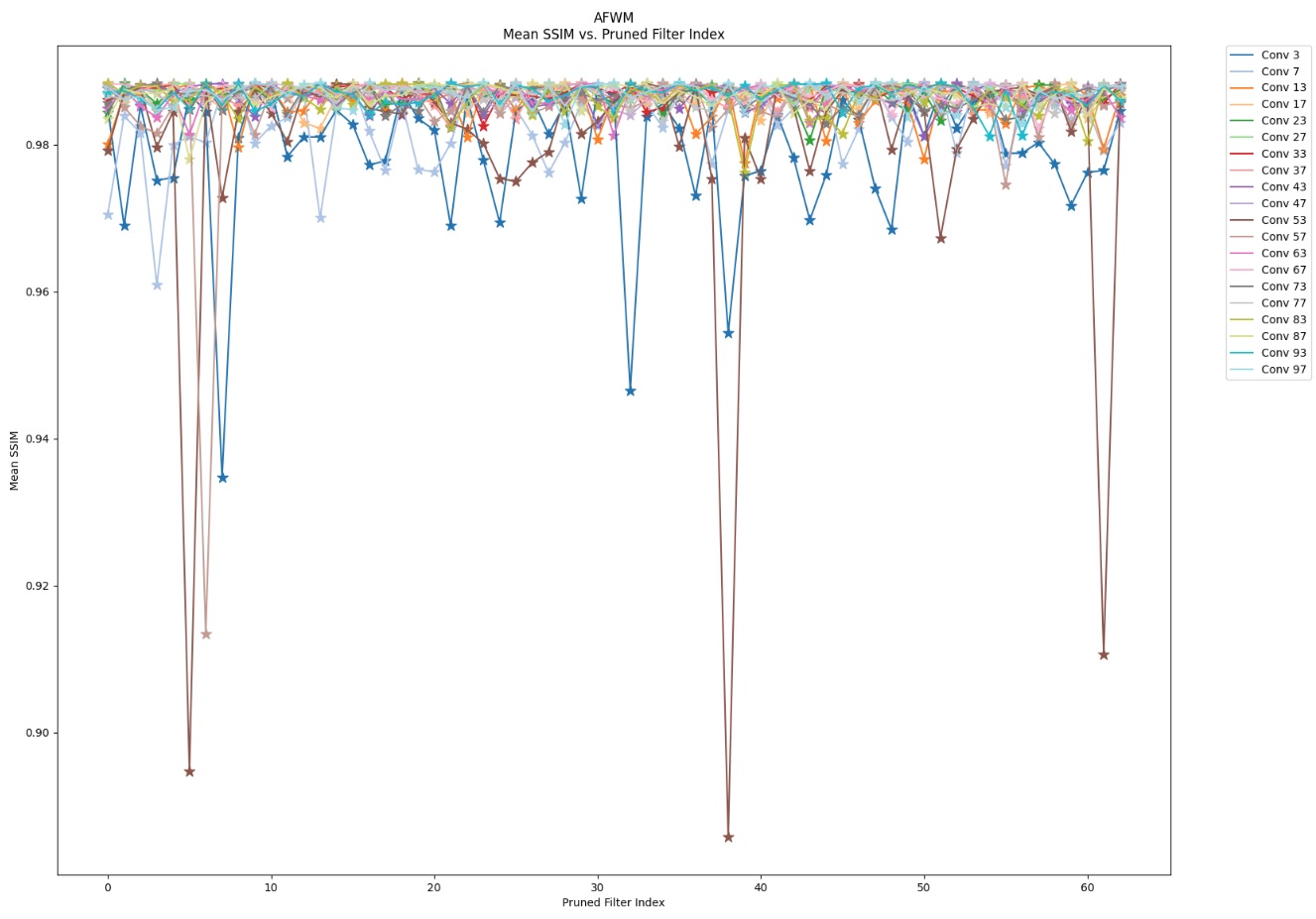
Unlike the sensitivity analysis conducted with unstructured pruning, I performed a sensitivity analysis on AFWM’s human condition feature encoder and clothing image fea- ture encoder using a structured pruning method. Structured pruning is a technique designed to compress a model by selectively remov- ing specific layers or weights of tensors within the model. Our structured pruning approach involves filter pruning, a variation of channel pruning. Tradition- ally, filter pruning is executed by ranking each filter within the layers using criteria such as L1-Norm or Entropy to assess the importance of each filter. Departing from this conventional method, I chose to run inference directly with our pruned model, systematically pruning one specific filter at a time. I pruned the first 64 filters per layer, given that the smallest convolution layers in the encoders, except for those in the downsampling block, have 64 output channels (filters). Since AFWM comprises multiple convolution layers, each followed by batch normalization, I had to adapt our architecture. Specifically, I adjusted the number of input channels for the first subsequent convolution layer by decreasing it by one. Additionally, I reduced the number of features for the first subsequent batch normaliza- tion, including its bias, running mean (moving mean), and running variance (moving variance), by one as well.
Through filter-wise structured pruning in a post-training regime, I have reached the conclusion that the mid layers in the encoders and networks within the Appearance Flow Warp Network are the least sensitive to pruning. In contrast, the initial layers are the most sensi- tive, as they capture the highest-level and global features of the input images. Furthermore, the performance drop after pruning the initial layers is attributed to specific filters within those layers. Therefore, the performance of the initial layer is dependent on certain filters, which I refer to as ’key-player’ filters. Pruning other filters may not have as significant an impact on performance. I propose that a carefully devised filter-wise pruning method, either structured or unstructured, targeting non-key-player filters, could result in model compression without compromising performance.
We have experimented with a model distillation technique to compress our model, with the primary goal of mini- mizing the impact on performance without the need for re-training. Our original model boasts over 70 million parameters, making the compression process crucial. The high-level overview of our model distillation strategy is as follows: Firstly, we compressed our generative model and warp model separately by reducing the number of channels within their respective convolution layers. Subsequently, we fine-tuned our compressed model (student) using sig- nals (outputs) extracted from the original model (teacher). To facilitate this process, we developed a custom loss function to compute errors between the teacher signals and student signals. We also conducted an extensive search for optimal hyperparameter combinations. This fine-tuning phase allowed our student model to learn effectively while being compressed, addressing the challenges posed by the large size of our original model.
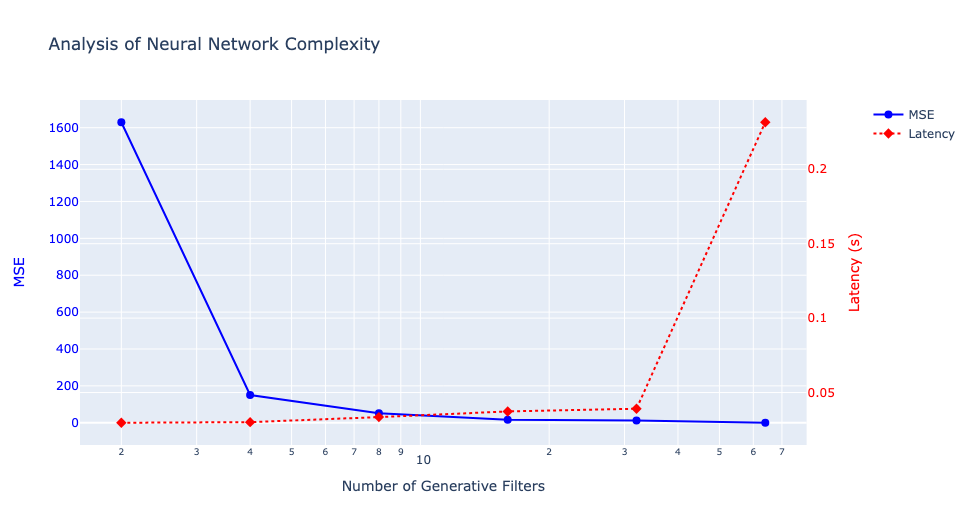
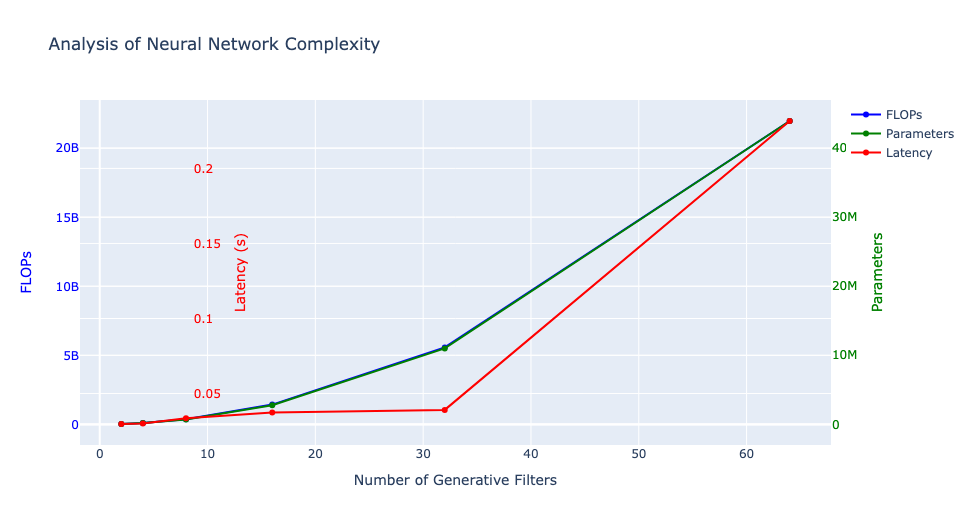
Before delving into distillation techniques, let’s first comprehend the significance of ngf, which refers to the number of generative filters in a neural network. These filters play a crucial role in determining the network’s ability to capture and display various features from the processed data, influencing the detail and complexity of the network’s output. Altering the ngf value can significantly impact the model’s parameters, as most layers in the network’s design depend on this value. We conducted tests with ngf values ranging from 2 to 64 to observe the network’s behavior, noting that the original model, as proposed by the authors, was trained with ngf set to 64. Subsequently, we utilized a custom loss function for fine-tuning a compressed version (student) of our generative model.
I compressed the warping model, which originally had 29 million parameters, by reducing the number of channels within its convolution layers. Specifically, I modified the configuration from [64, 128, 256, 256, 256] to alternative combinations. Each number in this list represents the count of convolution filters utilized in constructing convolution layers for either a feature encoder or a convolution layer within a refining pyramid feature network. To provide clarity, when the list comprises 5 numbers, there are 5 feature encoders dedicated to both human image and clothing condition, respectively. Additionally, there are 5 convolution layers within a refining pyramid feature network. The various combinations are detailed in the table below.
With the growing focus on urban air mobility, the development of next-generation air mobility systems has become a paramount area of research. This project is motivated by a semi-autonomous approach, where pilots remain within the aircraft, supported by advanced co-pilot systems to alleviate their workload during flight operations. To enhance adaptive co-pilot systems, a key aspect is identifying instances when pilots experience high workloads. One way to assess pilots’ mental and physical workloads during flight operations is to use various biometric data, such as heart rate, eye gaze, GSR, response time, etc., as inputs to a statistical estimator. In this project, we are developing a machine learning model to estimate pilots’ stress levels using physiological data measured during target flight operations.
Currently I am being involved in the development of a multimodal machine learning model aimed at estimating eVTOL (electric Vertical Take-off & Landing) aircraft pilot workload during various flight operations. As a member of a team consisting of researchers and engineers, we have been collecting multimodal biometric data (including Heart Rate, Eye Gaze, GSR, etc.) from pilots engaged in simulated flights with a VTOL aircraft. Our data collection process includes obtaining ground truth labels for pilot workload, gathered through pilots’ self-evaluation using the NASA Task Load Index (TLX) questionnaire. Additionally, we are currently engaged in signal processing of the collected data and working on building a multimodal machine learning feature extraction system to estimate pilot workload.
One of our objectives is to measure pilots’ mental and physical workload during flight maneuvers of VTOLs, the next generation of air mobility. Since this mode of air transportation has barely been commercialized, collecting biometric data while flying inside actual VTOLs is nearly impossible. Furthermore, this could pose a safety hazard, as physiological sensors attached to pilots can be sources of distraction during flights. For this reason, we collected data from pilots while they were flying inside a simulated environment, using Xplane12, a flight simulation game developed by Laminar Research.
For a more accurate estimation of pilot workload, we chose to collect seven different modalities of physiological data. These include heart rate, galvanic skin response, eye gaze, response time, body pose, brain activity, and grip force. Our experiment set up is inspired by the work presented in Objective Measures of Cognitive Load Using Deep Multi-Modal Learning: A Use-Case in Aviation (2021).
We collected heart rate using a wristband heart rate monitor.
We collected galvanic skin response by wrapping electropads around the fingers of the participants. These electropads are connected to a wireless GSR sensor.
We collected the participants’ eye gaze using eye-tracking glasses.
We collected the participants’ response time approximately every 15 seconds by activating a vibration motor attached to their collarbone. Participants were required to press a clicker whenever they felt the vibration.
We collected upper body joint poses in 3D spatial coordinates (x, y, z) using an Xbox Kinect camera.
We collected brain activity using an fNIR (Functional near-infrared spectroscopy) sensor. This sensor emits non-invasive near-infrared light to estimate cortical hemodynamic activity.
We collected the participants’ grip force during the simulated flight using two individual force-sensing resistor strips attached to the joystick.
Published in Journal 1, 2009
This paper is about the number 1. The number 2 is left for future work.
Recommended citation: Your Name, You. (2009). "Paper Title Number 1." Journal 1. 1(1). http://academicpages.github.io/files/paper1.pdf
Published in Journal 1, 2010
This paper is about the number 2. The number 3 is left for future work.
Recommended citation: Your Name, You. (2010). "Paper Title Number 2." Journal 1. 1(2). http://academicpages.github.io/files/paper2.pdf
Published in Journal 1, 2015
This paper is about the number 3. The number 4 is left for future work.
Recommended citation: Your Name, You. (2015). "Paper Title Number 3." Journal 1. 1(3). http://academicpages.github.io/files/paper3.pdf
Published:
This is a description of your talk, which is a markdown files that can be all markdown-ified like any other post. Yay markdown!
Published:
This is a description of your conference proceedings talk, note the different field in type. You can put anything in this field.
Undergraduate course, University 1, Department, 2014
This is a description of a teaching experience. You can use markdown like any other post.
Workshop, University 1, Department, 2015
This is a description of a teaching experience. You can use markdown like any other post.